複数routes、複数receiversなAlertmanagerConfigの書き方
ググってもパッと出てこなかったのでメモ。
結論から書くとこんな感じです。
ほとんどご自身の環境に書き換えてもらわないと使えませんが、
誰かの参考になれば幸いです。
結論
1apiVersion: monitoring.coreos.com/v1alpha1
2kind: AlertmanagerConfig
3metadata:
4 name: alertmanagerconfig
5 namespace: payara
6spec:
7 receivers:
8 - name: webhook-critical
9 webhookConfigs:
10 - sendResolved: true
11 url: http://192.168.0.60:8084/4b1e5d0c-e59b-4688-8e42-31f536364c6d
12 - name: webhook-warning
13 webhookConfigs:
14 - sendResolved: true
15 url: http://192.168.0.60:8084/dd947e3b-d2b5-4ad2-b150-84123a394486
16 - name: webhook-default
17 webhookConfigs:
18 - sendResolved: true
19 url: http://192.168.0.60:8084/0300020f-bfe0-4c7a-872c-0ccc070f244e
20 route:
21 groupInterval: 5m
22 groupWait: 30s
23 receiver: webhook-default
24 repeatInterval: 5m
25 routes:
26 - matchers:
27 - name: severity
28 value: critical
29 - name: namespace
30 value: payara
31 receiver: webhook-critical
32 - matchers:
33 - name: severity
34 value: warning
35 - name: namespace
36 value: payara
37 receiver: webhook-warning
以下のprometheusルールでテストしました。
1apiVersion: monitoring.coreos.com/v1
2kind: PrometheusRule
3metadata:
4 name: payara-rule
5 namespace: payara
6spec:
7 groups:
8 - name: payara
9 rules:
10 - alert: payara-cpu-utilization-critical
11 annotations:
12 description: Payara's CPU usage is over 90%
13 expr: >-
14 sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{namespace="payara",container="payara"}) by (pod) /
15 sum(cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits{namespace="payara",container="payara"}) by (pod)
16 > 0.9
17 for: 0s
18 labels:
19 severity: critical
20 namespace: payara
21 - alert: payara-cpu-utilization-warning
22 annotations:
23 description: Payara's CPU usage is over 80%
24 expr: >-
25 sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{namespace="payara",container="payara"}) by (pod) /
26 sum(cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits{namespace="payara",container="payara"}) by (pod)
27 > 0.8
28 for: 0s
29 labels:
30 severity: warning
31 namespace: payara
事前準備
こちら で構築したRKE2クラスターに Rancher Monitoring をインストールします。
root@k8s1:~# helm list -n cattle-monitoring-system
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
rancher-monitoring cattle-monitoring-system 1 2024-02-21 10:29:09.154807489 +0000 UTC deployed rancher-monitoring-103.0.3+up45.31.1 v0.65.1
rancher-monitoring-crd cattle-monitoring-system 1 2024-02-21 10:27:29.246121896 +0000 UTC deployed rancher-monitoring-crd-103.0.3+up45.31.1
今回はwebhookで通知テストすることにしたので、webhook.site
を利用しました。
arm64イメージはないっぽいのでVMにdocker-composeで自前で構築しました。
以下の部分です。
11url: http://192.168.0.60:8084/4b1e5d0c-e59b-4688-8e42-31f536364c6d
また、監視対象としてpayaraをdeploymentで2つ起動しました。
resourceのrequestとlimitは適当です。
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: payara
name: payara
namespace: payara
spec:
replicas: 2
selector:
matchLabels:
app: payara
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: payara
spec:
containers:
- image: payara/server-full:6.2024.2-jdk21
name: payara
resources:
requests:
memory: "1024Mi"
cpu: "1000m"
limits:
memory: "1024Mi"
cpu: "1000m"
準備ができたらGrafanaで以下のようにCPU Limits %が取得できていると思います。
(Rancher MonitoringならGrafanaやダッシュボードはすでにあるはず)
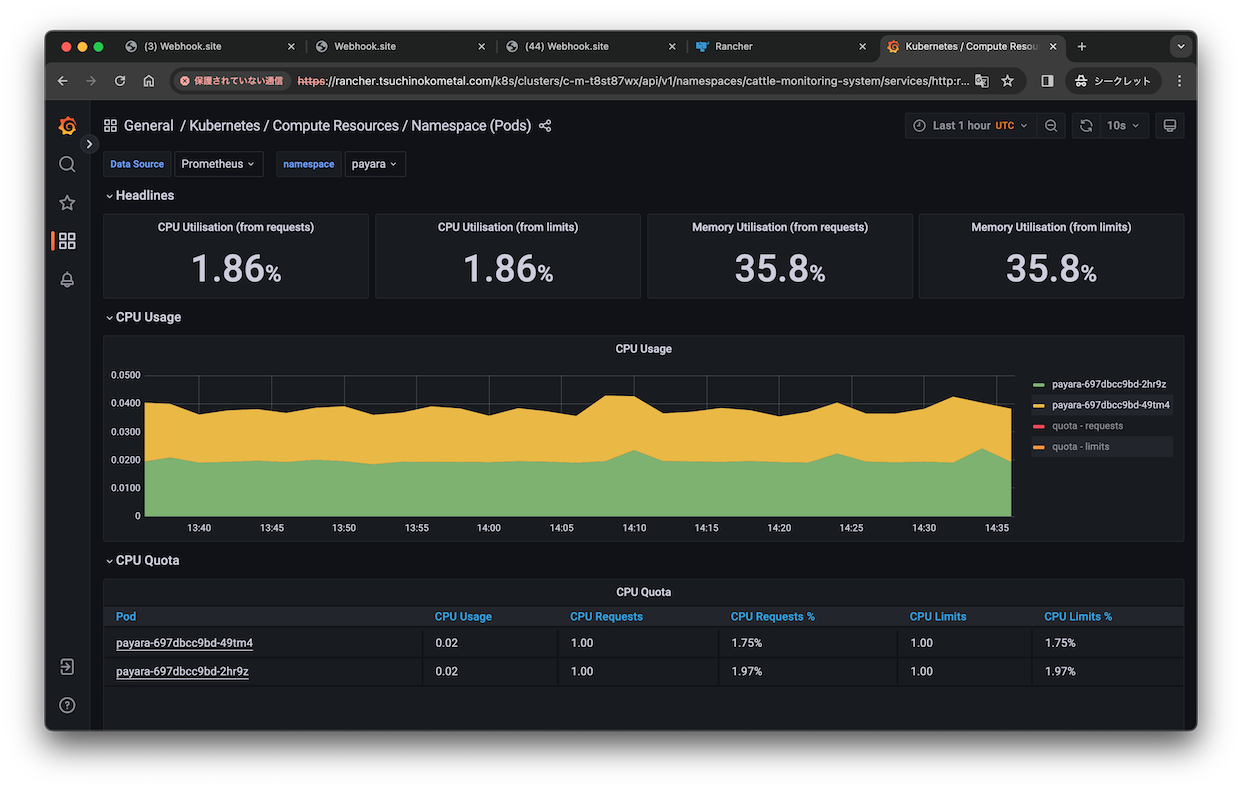
今回はこのCPU使用率でアラート発報します。
yaml解説
Rancher GUIのalertmanagerconfig設定画面には以下のメッセージが表示されており、
複数routeの設定は現状できないため、kubectlでyamlをapplyしてください。
This form supports configuring one route that directs traffic to a receiver. Alerts can be directed to more receiver(s) by configuring child routes in YAML.
今回は、
Payara PodのCPU使用率が90%以上でcriticalアラート、
80%以上でwarningアラートするルールにして、
それぞれ別のURLにwebhook通知する流れとしました。
prometheusRule:
-
prometheusRuleの検知式は、Grafanaダッシュボードの設定を拝借しました。
-
注意点としてnamespaceのラベルがないと通知されません。
18 labels:
19 severity: critical
20 namespace: payara
おそらくこちらのissue
だと思います。
ただ書いてあるとおり、rancher monitoringインストール時に、
alertmanagerに以下の設定を入れると不要になると思います。
alertmanager:
alertmanagerSpec:
alertmanagerConfigMatcherStrategy:
type: None
AlertmanagerConfig:
- デフォルトのreceiverを設定しないとうまく通知できませんでした。
23 receiver: webhook-default
- こちらにもnamespaceのラベル情報が必要です。
25 routes:
26 - matchers:
27 - name: severity
28 value: critical
29 - name: namespace
30 value: payara
発報テスト
一旦しきい値を0にしてfiringさせます。
これ強制的に発報することできないかな?
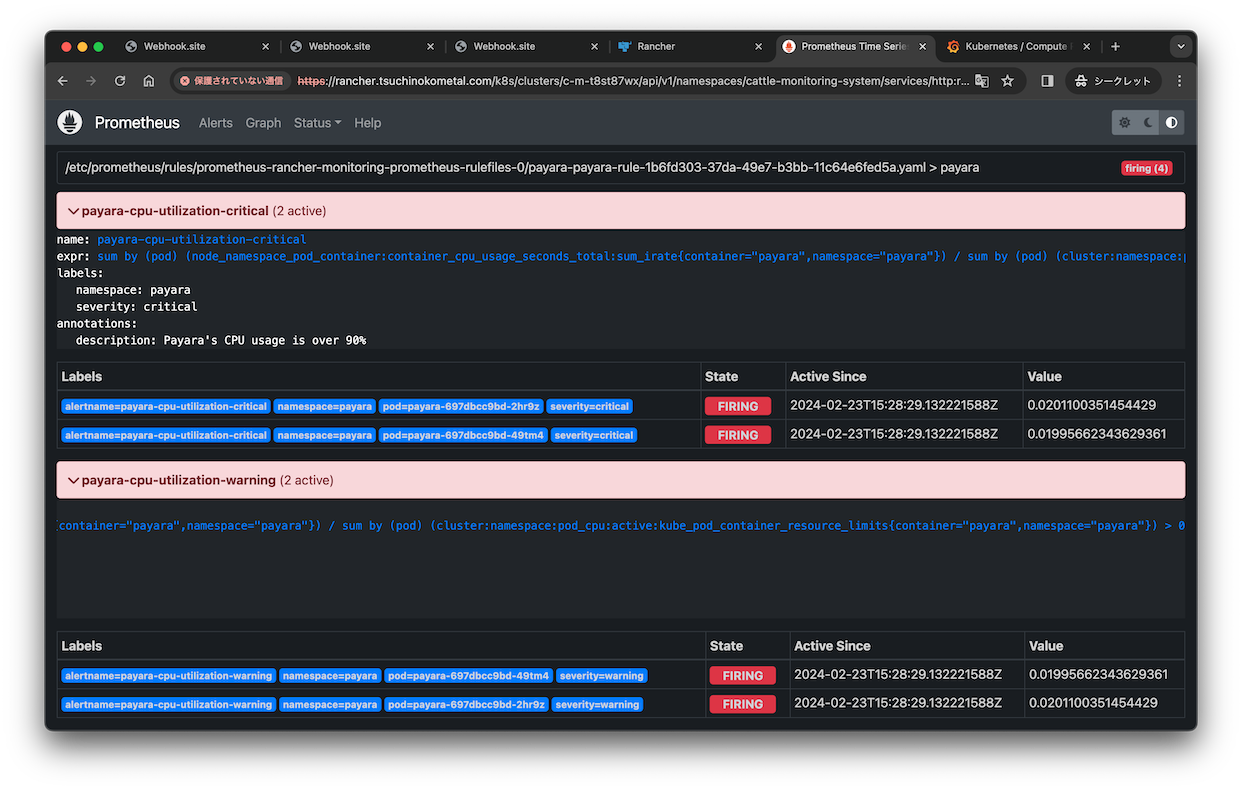
こんな感じに通知が届きました。
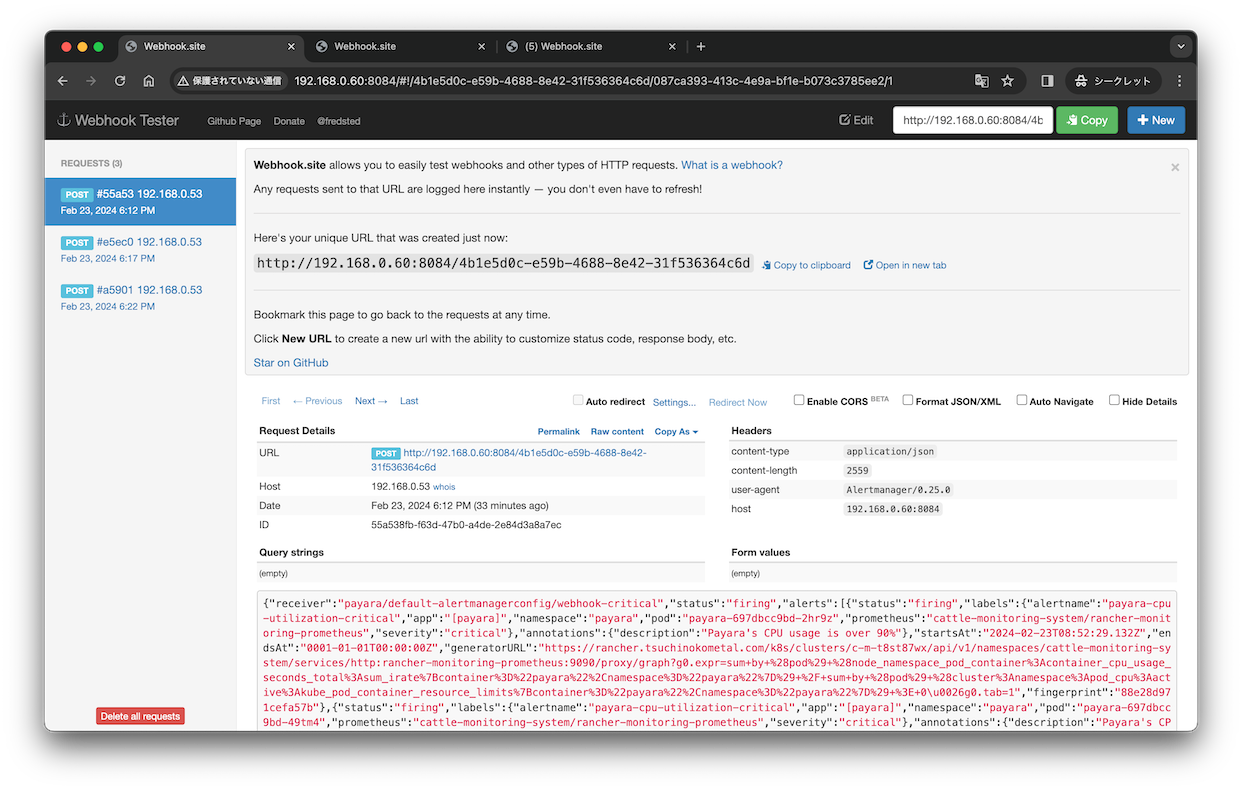
ひとまず良さそうですが、関係ない他のルールがfiringすると
デフォルト通知先に通知来ちゃいます。
これ通知しないようにできないかな?